On the right what you refer as ‘ESP32’ is Muse Proto (yellow board), correct?
Could you it be an issue with the Whisper model that is used and the processing power of the Raspberry pi 4?
i will also make a recording on the Luxe, but I think the quality is comparable to the Proto from what I remember. This is why I think it is more related to some settings tweaking. We have somebody of the team working on that subject this week, I will post result here.
no i mean a ESP32 D1 mini + INMP441 + MAX98357 (and 11 wires)
and yes it could very likely be a issue with whisper, there is lots of them (like not giving audio reply), i d believe it could be a matter of raising the gain, like i did with the ESP/INMP441. only did the 11db gain and have not tried on the muses.
it’s the microphone we discuss yes the sound is great on both luxe and proto, but for voice assistant to work it needs a good mic (gain), and even then whisper is horrible at “decoding” that to words, but it’s a work in progress, the year has many months left :))
Thanks I have installed this yalm on the luxe without issue I can play TTS, but not sure how to record when pressing the play button it seems the be in “Assist in progress” but where should I see the speech to text result?
i figured it out for the luxe, and for esp32, not proto, i just tried the same yalm from luxe on the proto and not sure what is different from luxe to proto, but lux finds a I2C device, proto does not:
Luxe:
[19:33:22][I][i2c.arduino:069]: Results from i2c bus scan:
[19:33:22][I][i2c.arduino:075]: Found i2c device at address 0x10
Proto:
[19:32:03][I][i2c.arduino:069]: Results from i2c bus scan:
[19:32:03][I][i2c.arduino:071]: Found no i2c devices!
what are you using? proto or luxe?, and sure i can send you the yaml i use in my Luxe if thats what you need :), or for ESP32+external I2S mic.
in settings, voice assistant, and the assistant you use (default), top right corner, debug. there yuo can follow as it goes along the pipeline.
i can play tts too, but i can’t get voice assistant to do it when replying, i can see in debug under raw that the result is created ready to be played bu nothing happens
In the meantime I used the yaml @DTTerastar posted earlier and it kind of works.
I had to change the GPIO12 parameter to be pulled up for the play button to work and changed the i2s_audio modul parameters to GPIOxx instead of just a number. I have a Luxe and it seems to work. So it sends something when I press the play button. Only problem it fails on STT with
[E][voice_assistant:145]: Error: stt-stream-failed - Speech to text failed
I tried to use the built in HA cloud based speech to text service which works on mobile phones and on the web interface.
In the logs I also saw this:
Voice error: Error processing en-AU speech: 400 No audio data received
So there is a chance that nothing is sent by the device or there is a network error somewhere.
Also would be great to understand how ESPHome sends the data to HA. I use a different subnet for Wifi clients and I hope it uses TCP or UDP not some non routable protocols. (I have found no documentation on this)
didn’t work for me, still no output from micrphone resulting in a “voice_assistant:145]: Error: stt-no-text-recognized - No text recognized” error. (and led turns red)
i think the problem is in reading the microphone? is it the same microphone in both luxe and muse?
btw. shouldn’t it be gpio0 for the button when it’s the proto
Thanks. Almost the same as mine. It should work in theory but I have a network issue.
Device is on a different subnet, HA runs in a docker with direct host network. I figured out the voice stream using UDP with 512kb packet stream just as I press the play button. It uses a random port on the destination side each time I press the button. Still yet to figure out what could be the problem (I let through every possible port for testing without luck). No real parameters for voice assitant on ESP home side to tweak I will open a ticket on github. Anyhow thanks again for sharing your config.
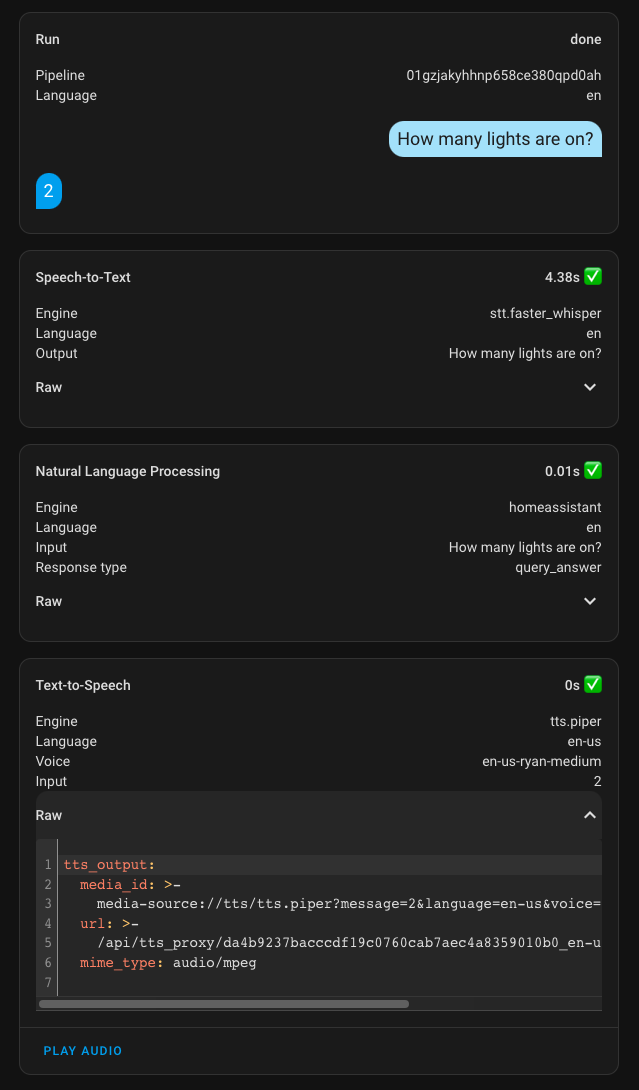
Ok I got the Speech to text (STT) part working here is the proof
I can only get the spoken sentence transcribed in the logs of the Muse Luxe.
I think the result is very good taking in account my French accent and the fact that I am using the simplest tiny int8 Whisper model running on a small Rapsberry pi 4.

")